Digging deeper into the analysis of Go-code
The analysis of source code at the syntactic level can help you with your coding in a variety of ways. For that, the text is almost always converted to AST first to make it easier to handle in most languages.
As some of you may know, Go has a powerful package go/parser, with it, you can convert source code to AST relatively easily.
However, I couldn’t help but be curious about how it is working, and I realized my mind could only be satisfied by getting started to read the API implementation.
In this article, I will walk you through how it is converted, by reading the implementation of its API.
Even those unfamiliar with the Go language don’t need to close the tab in the browsers, as this is a generic enough article to understand how programming languages are analyzed.
This article is also the first step in understanding the compiler and interpreter, as well as delving into static analysis.
AST
Let’s start with some of the knowledge you need to read the implementation. What is AST(Abstract Syntax Tree)? According to Wikipedia:
In computer science, an abstract syntax tree (AST), or just syntax tree, is a tree representation of the abstract syntactic structure of source code written in a programming language. Each node of the tree denotes a construct occurring in the source code.
Most compilers and interpreters use AST as an internal representation of the source code; AST typically omits semicolons, line feed characters, white spaces, braces, square brackets, and round brackets from the syntax tree, etc.
What you can do with AST:
- Source code analysis
- Code generation
- Can be rewritten
How to convert to AST
Plain text is quite straightforward for us, but from a machine, nothing is tougher to handle. Therefore, you have to first do lexical analysis the text with a lexer. The general flow is to pass it to a parser and retrieve the AST.
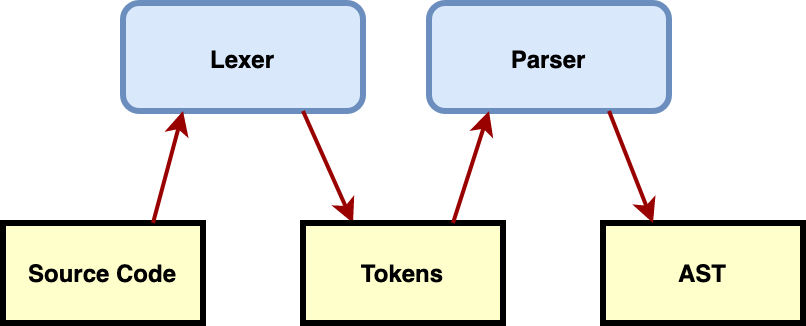
I’d prefer to point out here that there is not a single universal AST format which can be used by any parser.
For instance, x + 2 in Go is represented by:
*ast.BinaryExpr {
. X: *ast.Ident {
. . NamePos: 1
. . Name: "x"
. . Obj: *ast.Object {
. . . Kind: bad
. . . Name: ""
. . }
. }
. OpPos: 3
. Op: +
. Y: *ast.BasicLit {
. . ValuePos: 5
. . Kind: INT
. . Value: "2"
. }
}
Lexical analysis
As mentioned earlier, the analysis typically starts by passing the text to a lexer and then fetching the tokens. A token is a string with an assigned and thus identified meaning.
go/scanner.Scanner is in charge of the lexer in Go.
What is the identified meaning? Seeing is believing.
Let’s say you write:
package main
const s = "foo"
This is what happens when you tokenize it:
PACKAGE(package)
IDENT(main)
CONST(const)
IDENT(s)
ASSIGN(=)
STRING("foo")
EOF()
All tokens in Go are defined here.
Peeling away at the parsing API
To convert a Go source file to AST, just call go/parser.ParseFile as shown below:
fset := token.NewFileSet()
f, _ := parser.ParseFile(fset, "foo.go", nil, parser.ParseComments)
Now that we’ve figured out the conversion steps by the previous chapter, let’s actually read the internal implementation of that method! (The version of Go we refer to is 1.14.1).
Scanner.Scan() — a method for Lexical Analysis
How does Go perform lexical analysis? As previously mentioned, go/scanner.Scanner is in charge of the lexer in Go.
Thus at first, let’s take a closer look at that Scanner.Scan() method — which is called by parser.ParseFile() internally.
func (s *Scanner) Scan() (pos token.Pos, tok token.Token, lit string) {
... // Omission
switch ch := s.ch; {
case isLetter(ch):
lit = s.scanIdentifier()
if len(lit) > 1 {
// keywords are longer than one letter - avoid lookup otherwise
tok = token.Lookup(lit)
switch tok {
case token.IDENT, token.BREAK, token.CONTINUE, token.FALLTHROUGH, token.RETURN:
insertSemi = true
}
} else {
... // Omission
}
ch is the current character held by Scanner. Scanner.Scan() advances to next character by calling Scanner.next() and populates ch, as long as it is available as an identifier name.
The code above is for the case where ch is a letter; It pauses its advance as soon as it encounters a character that cannot be used as an identifier and then determines the type of token.
There are different ways to determine where does a single token start and where does it end, depending on the character. For instance, in the case of String, it continues to advance until " appears:
case '"':
insertSemi = true
tok = token.STRING
lit = s.scanString()
func (s *Scanner) scanString() string {
// '"' opening already consumed
offs := s.offset - 1
for {
ch := s.ch
if ch == '\n' || ch < 0 {
s.error(offs, "string literal not terminated")
break
}
s.next()
if ch == '"' {
break
}
if ch == '\\' {
s.scanEscape('"')
}
}
return string(s.src[offs:s.offset])
}
Finally, the Scanner.Scan() method returns a token that has been identified.
Parsing
Before taking a look parsing a file, let’s check the file structure in Go. According to The Go Programming Language Specification - Source file organization:
Each source file consists of a package clause defining the package to which it belongs, followed by a possibly empty set of import declarations that declare packages whose contents it wishes to use, followed by a possibly empty set of declarations of functions, types, variables, and constants.
That is, the structure is:
- A package clause
- Import declarations
- Top level declarations
After parsing a package clause and import declarations, parser.parseFile() repeats the parsing of the declaration to the end of the file.
for p.tok != token.EOF {
decls = append(decls, p.parseDecl(declStart))
}
So let’s look at parser.parseDecl next.
parser.parseDecl() — a method to parse the syntax of a declaration
parser.parseDecl() returns ast.Decl, the node of the syntax tree representing the declaration in the Go source code.
func (p *parser) parseDecl(sync map[token.Token]bool) ast.Decl {
if p.trace {
defer un(trace(p, "Declaration"))
}
var f parseSpecFunction
switch p.tok {
case token.CONST, token.VAR:
f = p.parseValueSpec
case token.TYPE:
f = p.parseTypeSpec
case token.FUNC:
return p.parseFuncDecl()
default:
pos := p.pos
p.errorExpected(pos, "declaration")
p.advance(sync)
return &ast.BadDecl{From: pos, To: p.pos}
}
return p.parseGenDecl(p.tok, f)
}
It goes through the tokens and process them differently for each keyword. Let’s deep dive into parseFuncDecl().
if p.tok == token.LPAREN {
recv = p.parseParameters(scope, false)
}
ident := p.parseIdent()
params, results := p.parseSignature(scope)
var body *ast.BlockStmt
if p.tok == token.LBRACE {
body = p.parseBody(scope)
p.expectSemi()
} else if p.tok == token.SEMICOLON {
p.next()
Internally, it advances the token by calling Scanner.Scan() — which we saw in detail earlier.
token.LPAREN represents (, so you can see that it starts parsing the parameters as soon as ( is found.
token.LBRACE represents {, so you can see that it starts parsing the function body as soon as { is found.
.
.
.
Oops, it’s going to take forever at this rate…
Summary
Parsing the tokens by myself has made me feel closer to the compiler and interpreter that I used to feel horrible about. I’d love to dabble in Writing A Compiler In Go and Writing An Interpreter In Go as well.