Realization of distributed tracing by Envoy
Necessity of distributed tracing
Since distributed architecture such as Microservices are handled across multiple services, it’s difficult to keep track of communication between services. For that reason,
- It becomes difficult to investigate the cause when a failure occurs
- It becomes difficult to investigate the cause of performance degradation
Distributed tracing solves these problems by visualizing communication.
Terminology
In learning distributed tracing, you need to remember the following two terms.
- Span: Processing within one service
- Trace: A collection of traces included in one request
Why Envoy?
It’s possible to realize distributed tracing without using Envoy if you have tools provided by a trace visualization provider such as Zipkin or Jaeger.
However, for realization, it’s essential to generate an identifier for each trace, propagate it, and send it to the collector component. It’s necessary to introduce client libraries for each language in each service, and implement it exclusively for that.
In the Microservice architecture, which is the distributed architecture on which Polyglot is premised, this will cause significant cost.
Therefore, if Envoy which is made on the basis of both inbound and outbound traffic is arranged as a sidecar, this problem can be solved and network and application can be separated.
People call an architecture that solves the problem unique to Microservices by making inter-service communication through sidecar proxy ServiceMesh.
However, it’s necessary to implement implementation to propagate specific identifiers within the application in order to properly propagate contexts such as parent-child relationships between spans. This will be described later.
Envoy’s tracing architecture
Depending on the trace provider you use, in most cases it will be an architecture consisting of the following components. Some providers provide storage, others need to operate on their own.
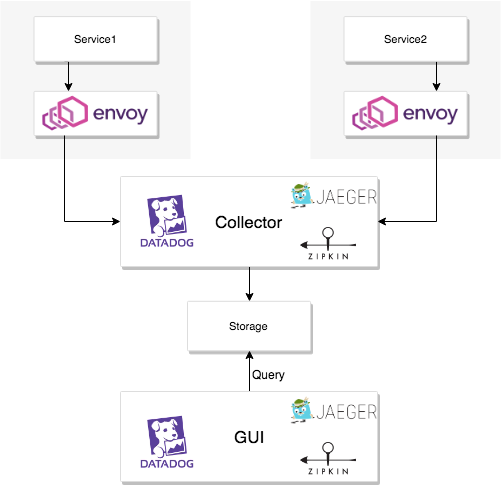
Generally, spans are associated by propagating unique identifier within a trace.
In this series of flows, Envoy has tasks which are roughly divided into three. Trace generation, propagation, and transmission to collectors.
Generation
Trace can be generated by setting tracing object.
Propagation
Envoy correlates the logging between the invoked services by propagating the identifier x-request-id.
And as mentioned previously, propagation of another identifier is required in order to define parent-child relationships between spans. And then Envoy puts this identifier in the HTTP request header. So you need to extract the identifier from a particular header and add it to the request header for the next service it communicates. In short, it’s necessary to modify the code a little.
As envoy has no way of associating outbound requests with inbound requests, this is the responsibility of the application developer.
Also, It’s better to read documents of provider you use since necessary identifiers for each trace visualization provider are different.
Transmission
At the time of this writing (December 14, 2018), trace visualization provider which of Envoy supports is as follows. Support for other tracing providers would not be difficult to add as Envoy is designed pluggable.
According to the document, specify the collector cluster to send the span. For example Zipkin, define as follows.
static_resources:
clusters:
- name: zipkin
connect_timeout: 1s
type: static
lb_policy: round_robin
hosts:
- socket_address:
address: 10.5.0.2
port_value: 9411
tracing:
http:
name: envoy.zipkin
config:
collector_cluster: zipkin
collector_endpoint: "/api/v1/spans"
Hands-on
Envoy offers a number of official sandboxes. I’d like to deepen the understanding of the flow of distributed tracing while using jaeger-tracing in this time.
Start services
$ git clone https://github.com/envoyproxy/envoy.git
$ cd envoy/examples/jaeger-tracing
$ docker-compose up -d
Three containers front-proxy, service1, service2 are started.
Send a request
$ curl -v http://localhost:8000/trace/1
\* Trying ::1...
\* TCP\_NODELAY set
\* Connected to localhost (::1) port 8000 (#0)
\> GET /trace/1 HTTP/1.1
\> Host: localhost:8000
\> User-Agent: curl/7.54.0
\> Accept: \*/\*
\>
< HTTP/1.1 200 OK
< content-type: text/html; charset=utf-8
< content-length: 89
< server: envoy
< date: Sat, 08 Dec 2018 06:10:24 GMT
< x-envoy-upstream-service-time: 27
<
Hello from behind Envoy (service 1)! hostname: 580a7e50d809 resolvedhostname: 172.18.0.5
\* Connection #0 to host localhost left intact
It will communicate in the order front-proxy, service1, service2.
Visualization
Point your browser to http://localhost:16686.
You should see multiple spans which are displayed as one trace.
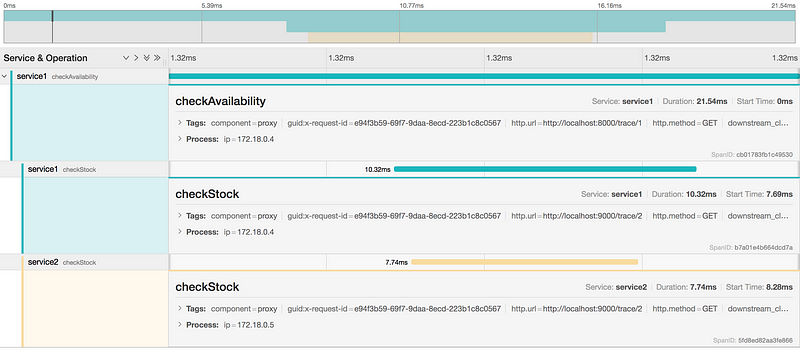
Modify implementation
An example implementation of the service is in examples/front-proxy/service.py.
The notable implementation is the following part, it propagates the received identifier by putting it on the header.
if int(os.environ['SERVICE_NAME']) == 1 :
for header in TRACE_HEADERS_TO_PROPAGATE:
if header in request.headers:
# Comment out here
# headers[header] = request.headers[header]
ret = requests.get("http://localhost:9000/trace/2", headers=headers)
For Zipkin compatible providers, this identifier is detailed in the repository B3 Propagation.
Let’s try commenting out this line and send a request again.
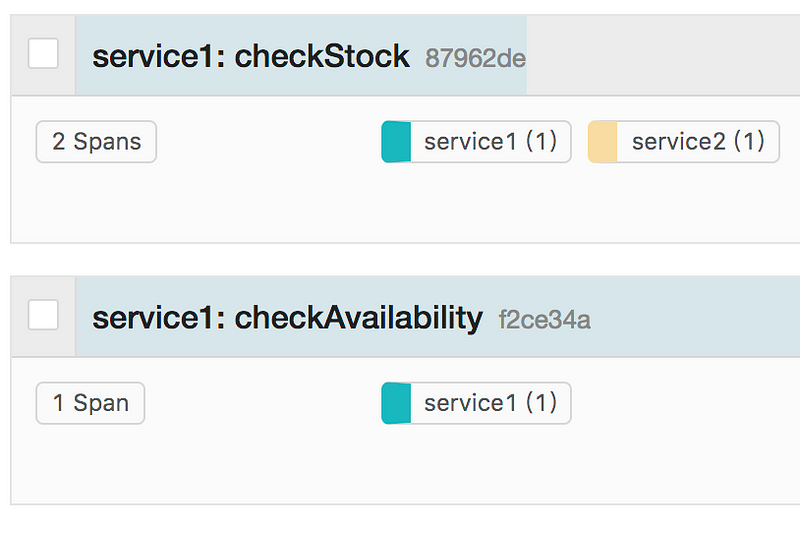
You could see that the spans are recognized as separate traces. We were able to confirm that it’s impossible to fetch a trace correctly unless the identifier is propagated between spans.
Future
Did you understand the rough mechanism by starting with the overall architecture and eventually touching the code?
Envoy has become the third project to graduate on November 28, 2018. Envoy’s goal is “to abstract the network from application developers so that they can focus on business logic” as mentioned repeatedly in the blog.
Not only Envoy, in these modern days when cloud native became mainstream many people want an environment where application developers can focus on creative activities.
The reaction to the project surpassed their wildest imagination when Lyft released Envoy as OSS in September 2016. This indicates that the network proxy occupies a very important position in promoting cloud native. A network proxy should always stay close to an application inside even if many projects which abstracts the network from the application will be started rapidly from now on. Therefore, deepening your understanding of proxies is very important in the cloud native era.
*I’d be grateful if you could point out mistakes and outdated knowledge on Twitter etc.